Tools, techniques, and the tech changing how we ship, delivered daily. No spam, ever.
Your daily AI & fullstack engineering briefing: top stories, tools, and research.͏͏͏͏͏͏͏͏͏͏͏͏͏͏͏͏͏͏͏͏
Sunday, 7 June 2026
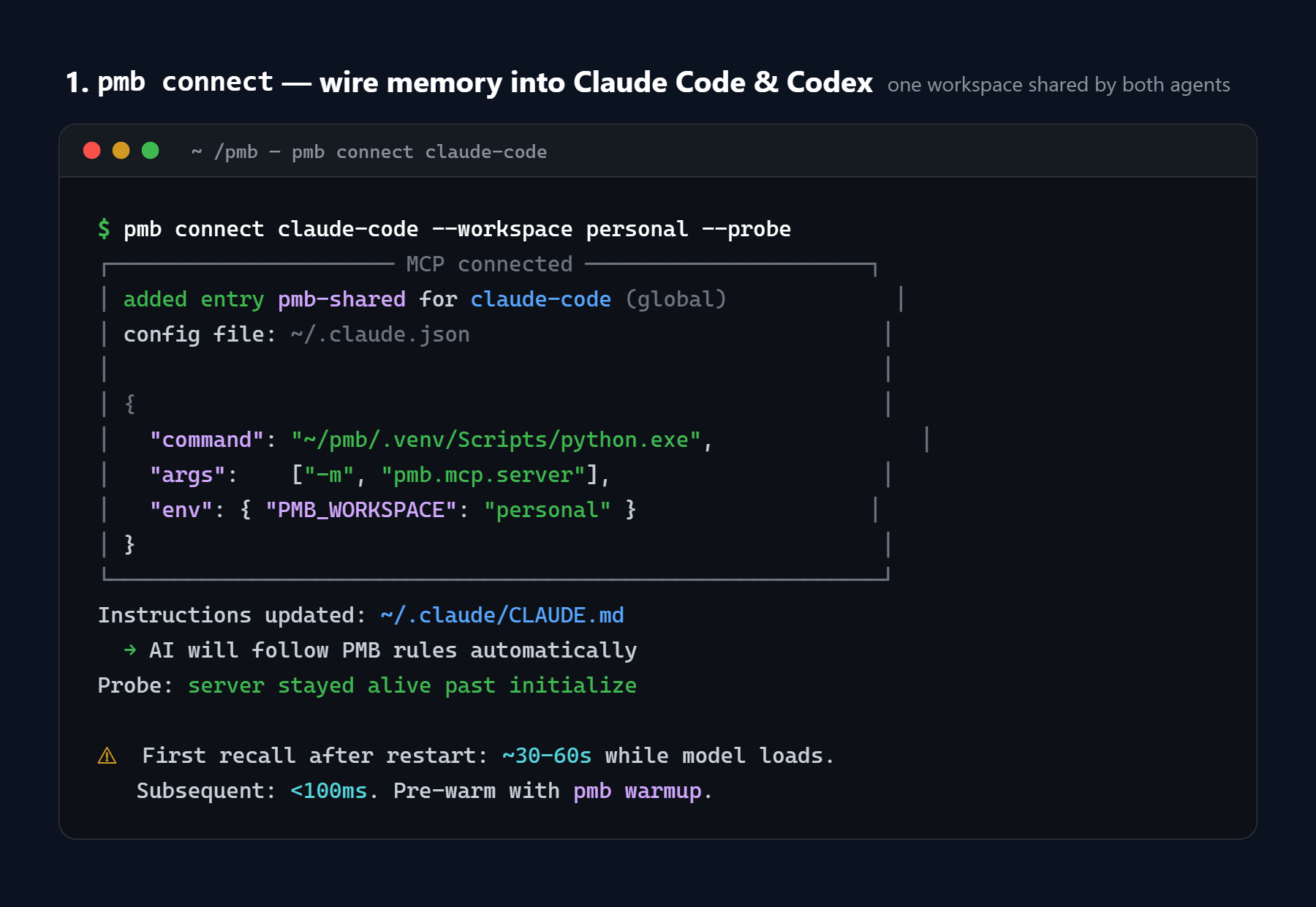
Edge-lm compresses Gemma 4 models by 7x to 1.4GB while preserving instruction following and tool use for edge deployment. PMB offers local-first persistent memory for AI coding agents with 94.5% recall and 70ms p50 latency across Claude Code, Cursor, and Codex.
Hackathon project runs emergent economy simulation where each agent uses different lab's small model, creating heterogeneous market behaviour.
Takeaway
Interesting proof-of-concept for agent diversity. Using different models per agent creates more realistic emergent behaviour than single-model approaches.
TheStageAI compresses Gemma 4 models by 7x to 1.4GB while preserving instruction following, tool use, and world knowledge for on-device deployment.
Bigger Picture
Compression Reality Check
The 7x compression claim for Gemma 4 comes with specific caveats: quality preserved on three key metrics but may degrade elsewhere. Still, 1.4GB fits mobile constraints.
Text-space optimiser that trains reusable natural-language skills for frozen LLM agents through trajectory-driven edits and validation loops.
Deep DivePythonAgentsLocal AI
Yesterday's Sentiment/Energised
Edge AI Gets Production-Ready
edge-lm delivers the compression breakthrough mobile AI needed, while PMB solves persistent memory with impressive benchmarks. MCP adoption accelerates.
Comprehensive MCP server for Bricks Builder with 100+ tools for pages, templates, styles, SEO, and content management via Claude Code and Cursor.
TrendingPHPMCPClaude
Learn/Multiple Mentions
What is MCP in AI development today?
MCP (Model Context Protocol) is Anthropic's standard for connecting AI models to external tools and data sources. Multiple projects like PMB, bricks-mcp-open, and totem show it's becoming the go-to way to give Claude and other models access to databases, APIs, and services.
Backboard's coding harness beats frontier models using open ones by prioritising memory and routing over raw model capability. R-CLI in open beta.
Takeaway
Build persistence into our AI workflows instead of chasing the latest model. 92% Terminal Bench with cheaper models suggests memory beats raw intelligence.
Under The RadarAI WorkflowsCost OptimisationTool Comparison
Complete solutions and notes for Andrew Ng's Machine Learning Specialisation on Coursera. and gaining momentum.
TrendingResearch
Learn/Core Concept
How does model compression actually work?
Model compression reduces AI model size through techniques like quantisation, pruning, and distillation without destroying performance. edge-lm demonstrates this by shrinking Gemma 4 from 10GB+ to just 1.4GB while preserving instruction following and tool use capabilities.