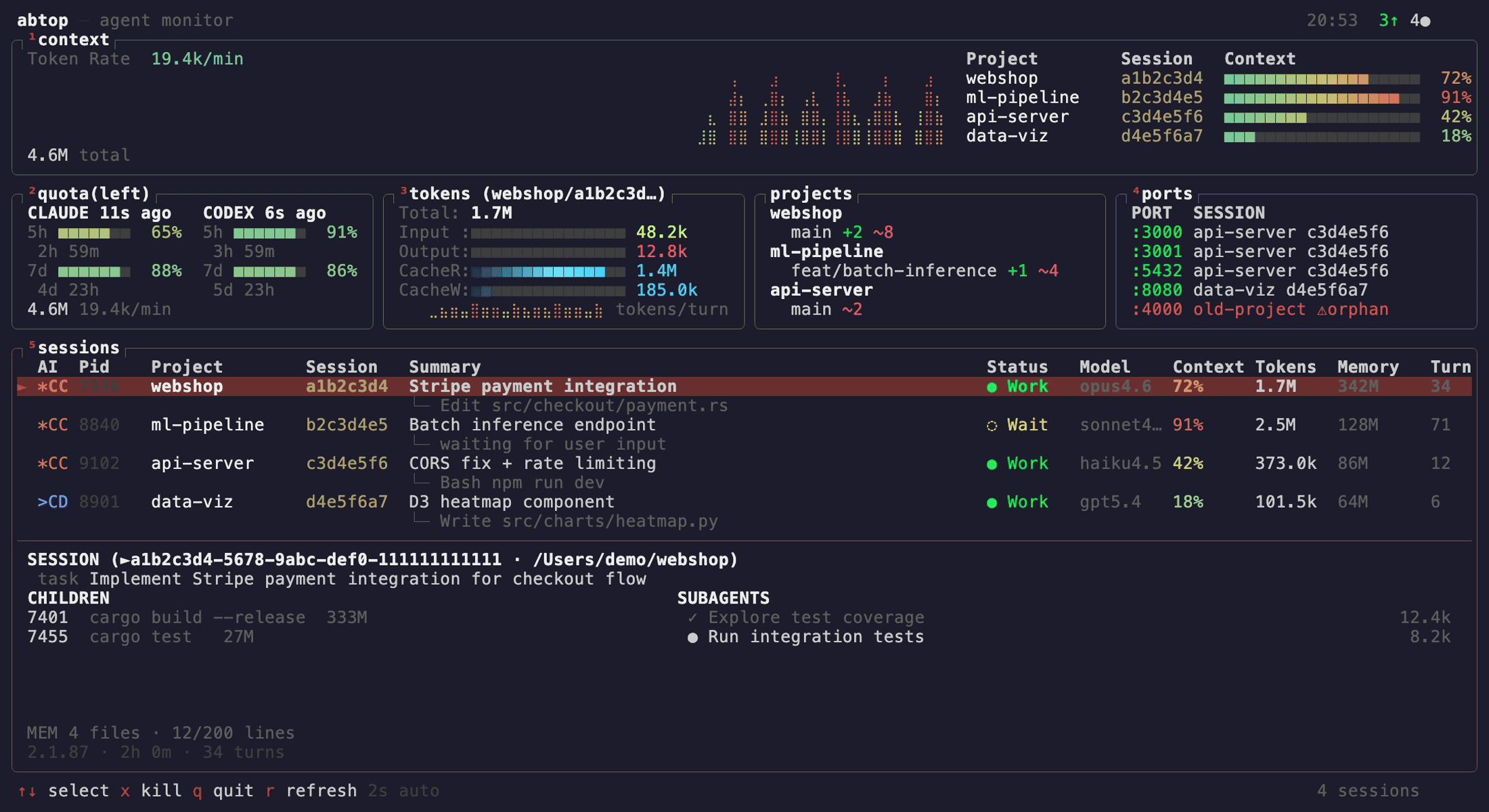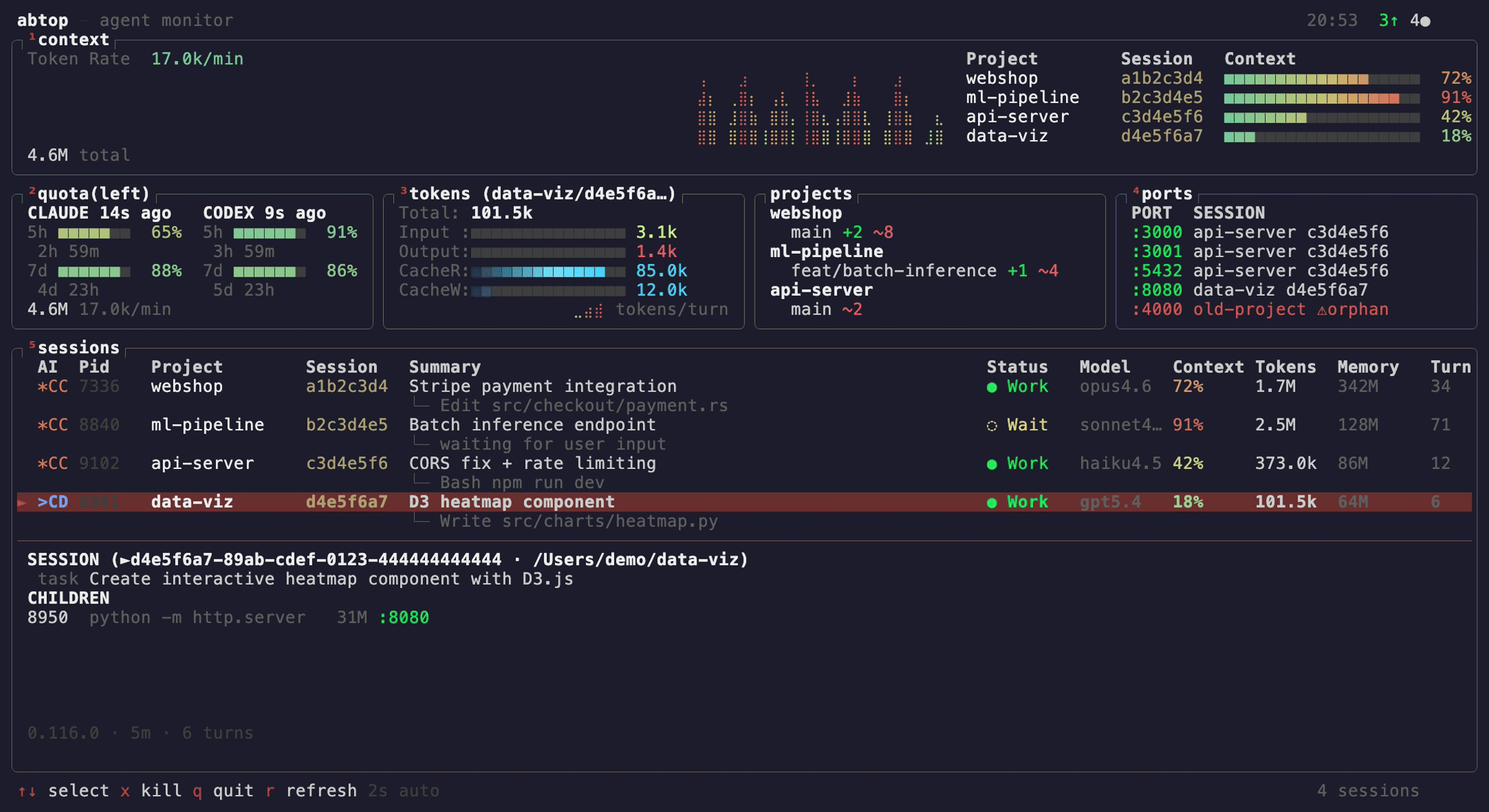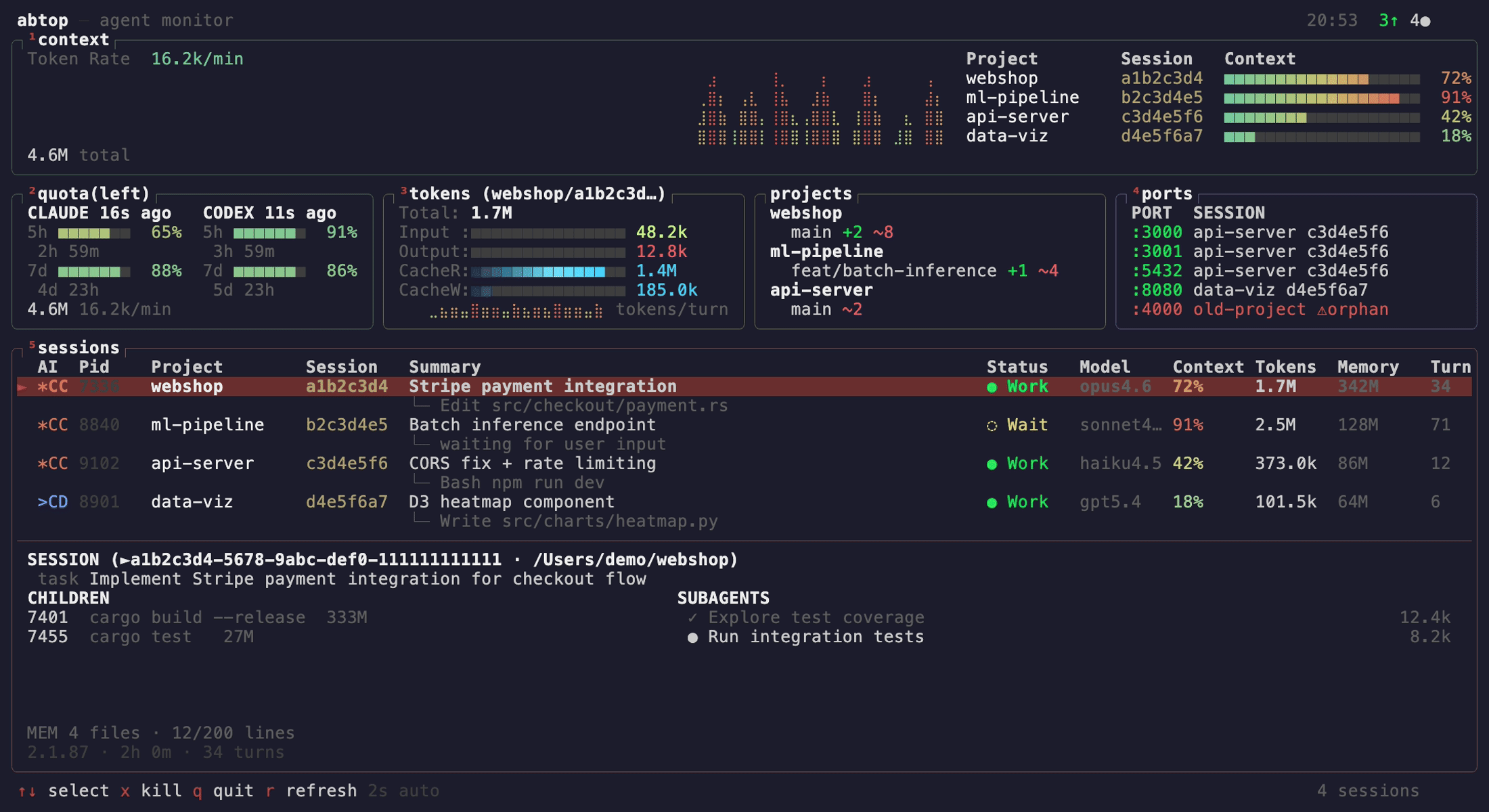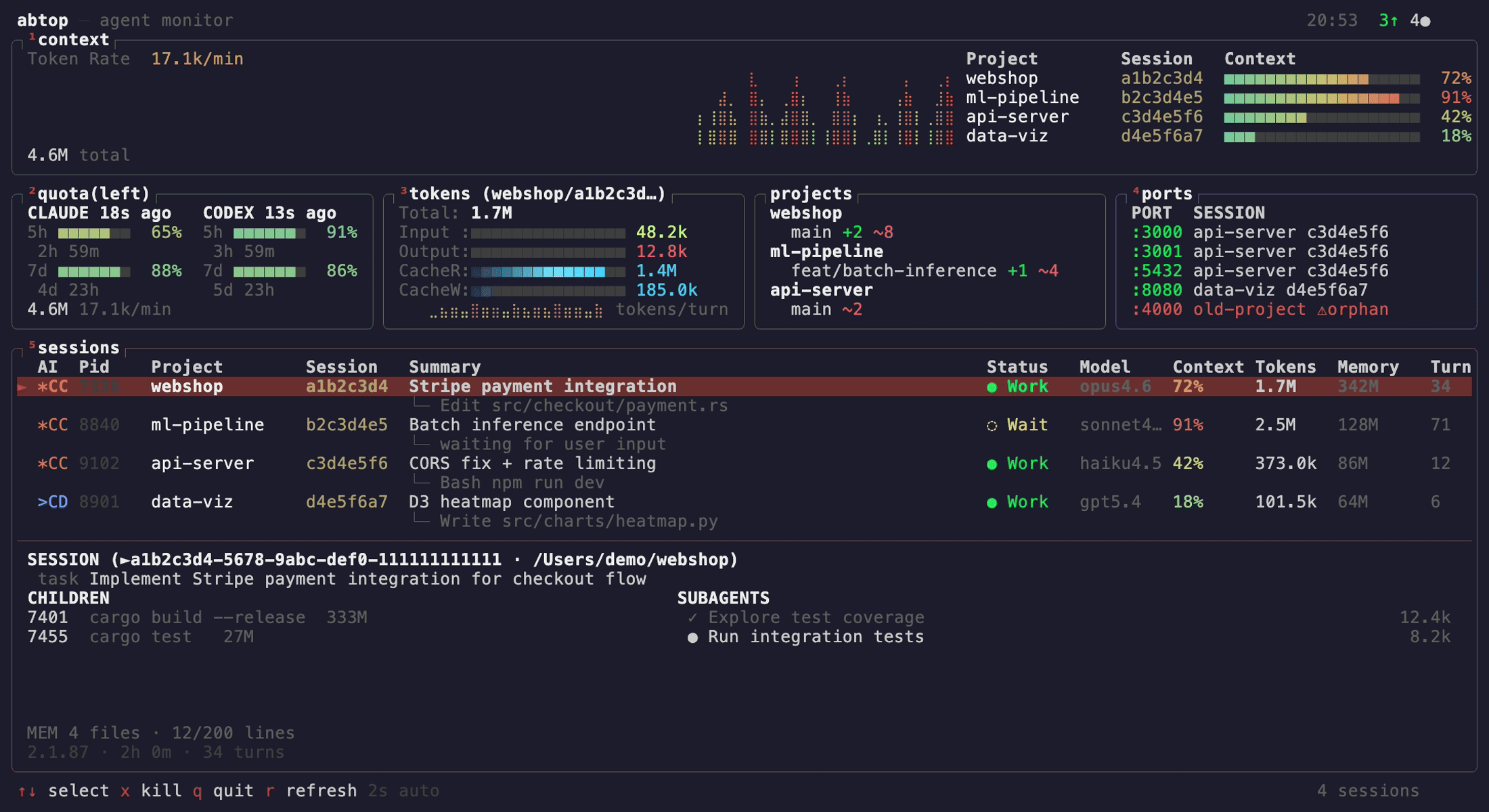
Learn/Core Concept How does inference caching actually work? Inference caching stores computed prefixes so repeated prompts don't recompute identical tokens. When we send similar requests, the system reuses cached computations up to the divergence point. inferoa shapes agent turns to preserve cacheable prefixes whilst TRACER routes easy inputs to fast cached models. This dramatically cuts costs and latency for agent workflows. KV-CachePrefixes |